This is unfortunate, but there a couple of things you can do about it. Let me describe this particular issue. Essentially, you have a dimension with a large number of attributes. In Excel, you have crossjoined many of these attributes on rows, which you feel is reasonable since you have also added a filter so that the query will only return a small number of rows. For example, here is a query of the FoodmartFull database, where I have filtered on just one customer surname (Peacock) and asked for many customer attributes on rows. This query takes 9 seconds for SQL Server 2008 to execute. The reason it takes so long is that the MDX is asking for a crossjoin of all the attributes, at all levels. Note, this issue can be so bad that the results are not returned before timeout.
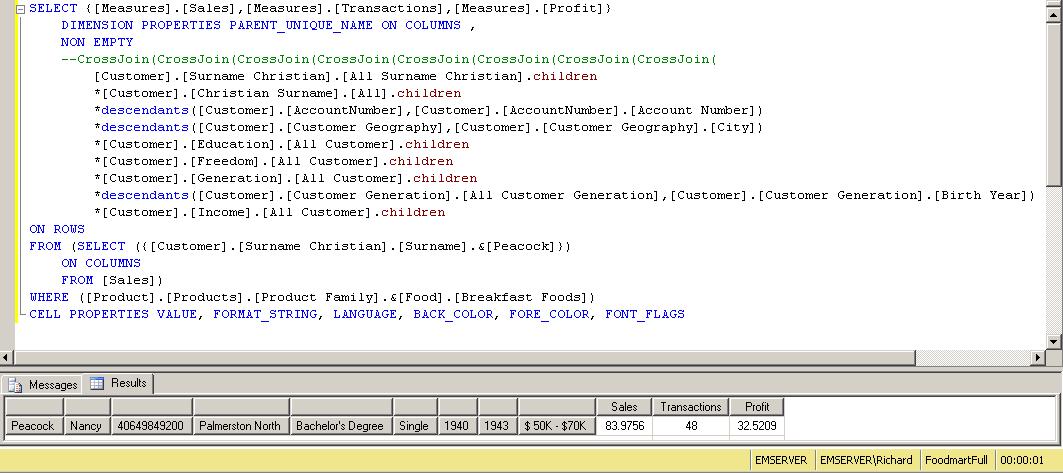
 I have traced the MDX using SQL Profiler. See the MDX in the picture to the
I have traced the MDX using SQL Profiler. See the MDX in the picture to the right. (I have formatted the MDX. Wouldn't it be a nice thing if SQL EM would format SQL/MDX for us? That's a topic for another blog.) If you execute this MDX, you will receive 3840 rows! That is a huge number, when you consider there is only one customer and Excel is only displaying 1 row. (I asked for a tabular format. But even if I ask for a compact format, I only get 14 rows.) Understandably, this MDX takes 14 seconds to execute.
right. (I have formatted the MDX. Wouldn't it be a nice thing if SQL EM would format SQL/MDX for us? That's a topic for another blog.) If you execute this MDX, you will receive 3840 rows! That is a huge number, when you consider there is only one customer and Excel is only displaying 1 row. (I asked for a tabular format. But even if I ask for a compact format, I only get 14 rows.) Understandably, this MDX takes 14 seconds to execute.The reason I chose this particular query is that all of the attributes you see in the Excel report are from the same dimension. Having all these attributes from the same dimension should be very easy for Analysis Services to return quickly, since it can determine, from the dimension, exactly which Customer cells/aggregations it needs.
I can edit the MDX to simply ask for the crossjoin of the leaf members, which will execute in just 1 second. This is much easier for Analysis Services since we are only asking for asingle row rather than 3840. See the second query. 
Of course it is not possible to edit Excel's MDX to make the query faster, but we do have other tricks we can employ. Since the problem is that Excel is inefficiently crossjoin-ing all of the attribute hierarchy sets, we can help Excel by creating a "whopper" user hierarchy that includes all (or many) the attributes we want in our report. If we had a Customer hierarchy with these attributes, Excel wouldn't need to ask for any (or so many) crossjoins and the query will be sub second. Of course, I am not suggesting that you create "whopper" hierarchies all over the place, but it is a consideration. Also note, you do not need to create one "whopper" hierarchy, just a couple of multi-attribute hierarchies might do the trick. This is because the cost of adding (or reducing) the number of hierarchies has an exponential effect on query performance. Each attribute you add will crossjoin the new set (it is not a single member set) with all other rows.
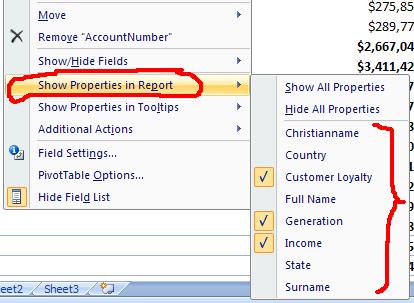 Another, much cleaner, option, if possible, is to simply show properties of existing members, rather than ask for a crossjoin. I say, if possible, as this is only possible if the parent attribute is in the report. Naturally, this is much more efficient, as the generated MDX is simply asking for the member properties of existing members (crossjoin not required).
Another, much cleaner, option, if possible, is to simply show properties of existing members, rather than ask for a crossjoin. I say, if possible, as this is only possible if the parent attribute is in the report. Naturally, this is much more efficient, as the generated MDX is simply asking for the member properties of existing members (crossjoin not required).Whenever there is an Excel performance issue, I would encourage you to trace the MDX using Profiler. Even though you can't directly change Excel's MDX, it will help you understand the problem and give you some ideas to work around it.
For a list of Excel PivotTable tips see http://richardlees.blogspot.com/2009/10/excel-2007-olap-pivottable-tips.html

3 comments:
It appears that this has been fixed in Office 2010
Hi Richard,
Great post. I just posted a follow up on similar issue & work around here
Feel free to send feedback.
Kind regards,
Rui Quintino
We have a cube that's pretty slow in Excel 2013. Tableau 8.1 runs like a dream. Shame.
Post a Comment